基于大数据的用户行为预测在前端性能优化上的应用
首先,我得说,这篇文章有点标题党了,其实内容并没有标题看起来那么高大上。其次,本文只是做一个技术方案可能性的探讨,并没有提供完善的解决方案,至多给了一个 Demo 供参考。
目的
前端性能优化,我觉得最主要的目的就两个:1、提升页面加载速度;2、节约服务器资源。
这里特别提一下节约服务器资源,很多人在做前端性能优化的时候,往往只考虑前端性能的问题,而完全忽视前端的性能优化对后端服务器性能的影响。其实,对于一个网络流量比较大的站点来说,节约服务器资源就是省钱啊。比如,js 文件、图片文件的大小越小,服务器所需的磁盘 IO 贷款和网络 IO 贷款也就越小,自然就可相应省下部分开支了。
现有的方法
前端性能优化,我们目前主流的技术方案主要也就两个:1、合并;2、压缩;3、缓存。
举个例子,一个网站有 A,B,C,D 四个页面,分别需要引用 a\b, a\b\c, a\b\c\d, a\d 这几个 js 文件。于是我们考虑到 a 这个 js 文件在四个页面中均有引用,所以不参与合并。然后把 b\c 两个 js 文件合并成 x,把 b\c\d 三个 js 文件合并为 y。现在 A,B,C,D 四个页面对 js 文件的引用规则变成了分别引用 a\b, a\x, a\y, a\d 这几个 js 文件。接下来,我们将 a\b\x\y\d 这五个 js 文件分别混淆压缩。
通过以上一系列的处理,现在用户通过浏览器访问我们的站点的时候,在 A\B\C\D 四个页面都只需要发起两个对 js 文件的请求。同时,四个页面还可以共享对 a 这个 js 文件的缓存。
现有的问题
上述的这个性能优化方案,我想很多人一眼就可以看出来,其实还存在很多问题。
1、首次加载页面时,缓存策略无法发挥作用,拖慢了页面加载速度。
虽然我们配置了缓存策略,使得用户访问过 B 页面一次之后再访问 B 页面是可以从浏览器缓存中直接加载其依赖的 a\x 两个 js 文件的。但是,如果用户只访问过 A 页面而没有访问过 B 页面,此时再访问 B 页面的话,只有 a 的缓存能够生效,而 x 是没有缓存的。
2、b\x\y\d 这四个 js 文件的内容存在冗余,浪费了服务器资源。
x 包含了 b\c 两个 js 文件的内容,但当用户使用浏览器请求了 x 之后再请求 b,任然需要重新下载整个 b 文件,这里对 x 的缓存是无法使用在 b 上面的。
从这两个问题来看,似乎我们还有进步的空间!
新方法
针对上面的问题,我们一个个来解决。
首先是首次加载页面时缓存策略无法发挥作用的问题。其实这个问题也是本文的核心,我的解决方案是预加载。也就是说,当用户还没有访问 B 这个页面的时候,我们就预先让用户的浏览器加载 B 页面所依赖的 x 这个 js 文件。
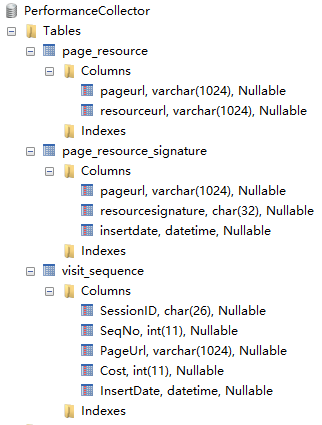
我设计了一个前端资源预加载系统,包括前端 js 代码、后端预加载策略逻辑,还有用于计算加载策略的数据库。还是用上面的那个例子。假设 A 页面是网站的首页,当用户访问 A 页面后,前端 js 将用户的 SessionID 和当前页面的 URL 发送到后端,并由后端逻辑将这条访问行为记录到数据库的 visit_sequence 表,然后收集前端资源形成资源列表,包括页面中引用的 link、script 等,并计算此资源列表的 MD5 发往后端进行比对。后端逻辑根据页面 URL 在 page_resource_signature 表中查找相应的 MD5 值,如果没有找到,就要求前端 js 代码发送整个资源列表以及页面 URL 和资源列表的 MD5 值并记录到 page_resource_signature 和 page_resource 表中;如果根据页面 URL 找到记录但 MD5 值不匹配,则要求前端 js 代码发送整个资源列表以及页面 URL 和资源列表的 MD5 值并并更新 page_resource_signature 和 page_resource 两个表中的数据;如果根据页面 URL 找到记录且 MD5 值也匹配,则后端程序根据数据库中 visit_sequence 表和 page_resource 表的记录,计算出用户在当前页面下访问系统中其他页面资源的可能性,并返回给前端代码逻辑,接下来,前端代码预加载后端返回的预加载资源列表中的资源。
前端代码:
1 | /* |
数据库表结构:
序列图:
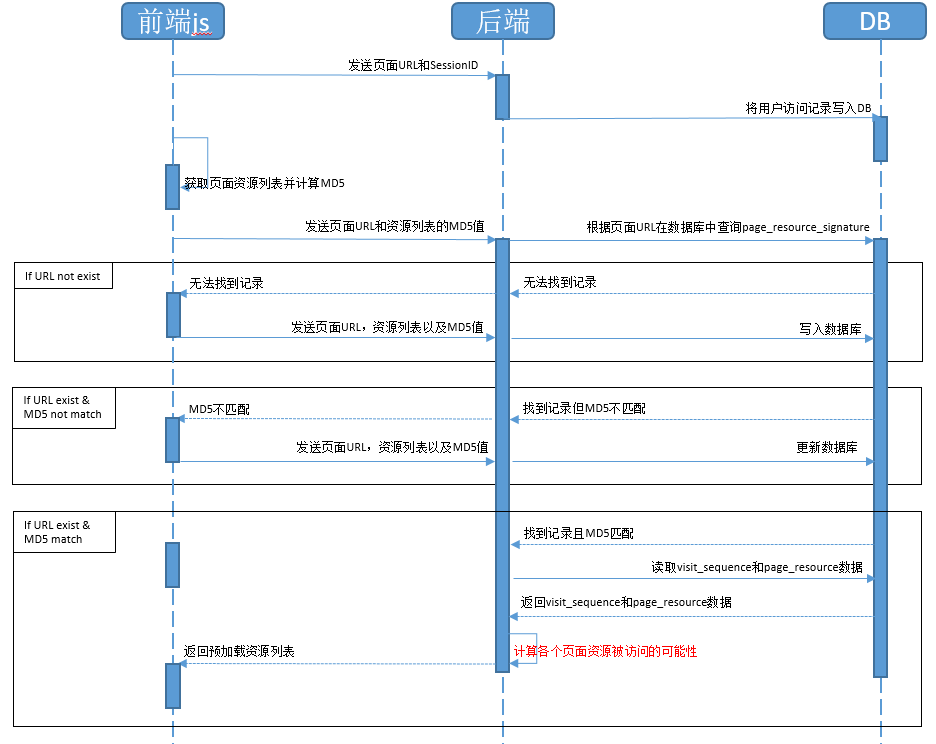
上述这个流程中,最关键的步骤就是“计算各个页面资源被访问的可能性”这一步了,也就是序列图中标红的部分。这个动作可以通过用程序分析用户以往的浏览记录来实现。比如我们常见的 Piwik 系统中,就直接提供了每个页面的上下游关系:

如上图,我们可以通过 Piwik 的接口清晰的看到,访问 index.php 这个页面之后,有 37%的用户接下来会访问 xxxx/xx=attendance&menuid=19 这个页面,还有 20%的用户接下来会访问 xxxx/xx=ast&a=index&menuid=30 这个页面。加入这两个页面都引用了 sharelib.js 这个文件,那么用户访问 index.php 这个页面后,需要访问 sharelib.js 这个资源的可能性就高达 57%,那么我们是不是就可以让 index.php 的前端代码预先加载 sharelib.js 这个资源呢?这样当用户真的发生页面跳转去浏览别的页面的时候,很可能跳转后的页面所需的前端资源我们已经预先加载过了,浏览器可以直接从缓存中读取相应的数据,从而实现加快页面加载速度的效果!
由此,通过详细记录用户浏览站点的行为,并分析每个页面的资源引用情况,我们就可以实在在用户访问某个页面之前就预先判断出那先资源是值得预先加载的。从而实现资源预加载的效果。
我们再来看第二个问题,也就是资源合并导致的内容冗余问题。
其实,当我们解决第一个问题的时候,第二个问题也就不复存在了。因为我们可以在用户进入页面之前就预先加载页面的资源,所以前端资源的合并也就没有存在的必要了,也就不存在因资源整合导致的内容冗余问题了。
新问题
这个新的方案虽然解决了我们的一些问题,但也并非完美无缺。
1、团队协作更复杂
以往的前端性能优化方案中,我们往往只需要一组前端开发人员参与就行了,可是现在的这个方案,由于需要后端提供用户行为预测的数据,所以很可能需要后端开发的同学也参与进来。如果站点的用户数据收集是专门的团队进行的,那么很可能还需要这个专门的团队参与整个方案的设计和实施。这无疑大大增加了团队协作的复杂度,对项目管理水平的要求进一步提高。
2、对站点首页没有任何效果
基于用户行为预测的优化方案,只有在用户进入站点之后才能生效,如果用户根本就没有进入站点,我们就什么都做不了了,所以,网站的首页在这种优化方案中完全得不到任何好处。而网站的首页往往又是整个站点中受访量最大的几个页面之一,所以这个问题带来的影响还是比较大的。
3、需要权衡数据实时性和性能
服务端在返回给前端用户接下来可能需要访问的资源的时候,是实时地通过数据库中的数据计算出各个资源被访问的概率,还是我们通过某种机制事先计算好然后直接读取返回给前端?如果是实时计算,可能概率的准确性会更高,但是用户访问的历史数据太多的话,这个实时计算是否会消耗过多的系统资源又是个大问题,而如果我们事先计算好这些数据,当站点页面更新的时候,若这些计算的概率数据没有更新,则用户在访问我们的站点的时候,就无法享受到预加载带来的好处,而且会因为我们放弃了传统优化方式而获得更糟的用户体验,那么这些概率数据什么时候才能得到更新又是个问题。
此文完全源于本人的一个脑洞,就是忽然灵光一现,想到了这个性能优化的方案。我在网络上尝试搜索相关的关键字,但是并没有找到很好的资料,所以我想,难道这还是我首创的?如果真是,那肯定还有很多没有考虑到的细节和不足,写出来供大家参考。如果不是,那还请各位过来人不灵赐教分享你的实践经验!